
目次
はじめに
こんにちは、TC3 AIチームの@mumeco_mlです!弊社は2022/10からGCP Cloud Partnerとなっておりまして、現在GCP(Google Cloud Platform)のプロジェクトでの活用をより促進しております。今回は、このGCPの機能の1つであるCompute Engineを利用したAI開発環境の作り方をご紹介いたします。GCPのVMで開発環境を作る場合、大きく分けて事前にML用に用意された環境を利用する方法と、Dockerを使ってOS環境等も含めて作る方法があると思いますが、今回は前者を説明します。需要があれば、後者の解説も作ろうと思います。
クラウド開発環境の利点・欠点
利点
- 高額なGPUをオンデマンドで効率的に活用できる
- ローカルマシンの動作が重くならない
- 任意のマシンスペックを利用できる
欠点
- 使用時間に応じて課金される
- 実際に開発するまでに環境構築に時間がかかる
- 毎回Python環境を作る必要がある
- CUDAやCuDNN等のGPUライブラリをインストールしないといけない
- git等の設定
- ネットワークが繋がっている必要がある
GCPにおけるVM環境の作り方
GPUを使いたい場合
GCPのVMにおいてGPUを使いたい場合はまず最初にGPUの使用数の申請が必要です。
まず、以下の図のように左のメニューのIAMと管理->割り当てを選択します。
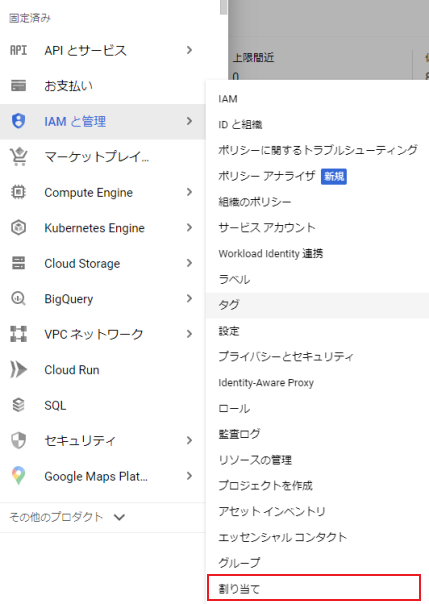
この割り当てページではGCPの様々なリソースの上限を設定できるので関係ないリソース情報が表示されています。なのでフィルタ部分にGPU名を入力して表示内容を減らします。今回はT4を使用する想定でT4と入力すると、以下のようにフィルタ名の候補が出てくるのでこのうちNVIDIA T4 GPUsを選択します。
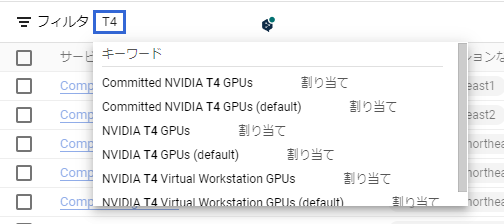
そうすると次のようにリージョン別でT4の使用可能数が表示されます。自分の環境だと既に上限が4になっています。これはこのプロジェクトにおいて同時に4個までT4を使用できるという意味です。もしこの値が1になっており、あなたが1つしかT4を使用しない場合は特に申請は必要ありません。
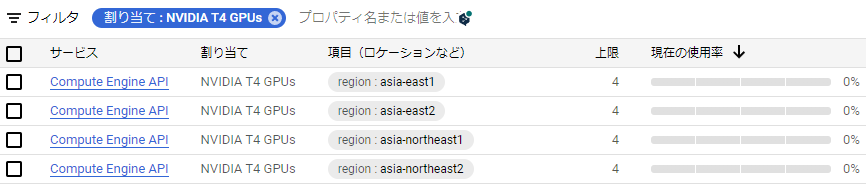
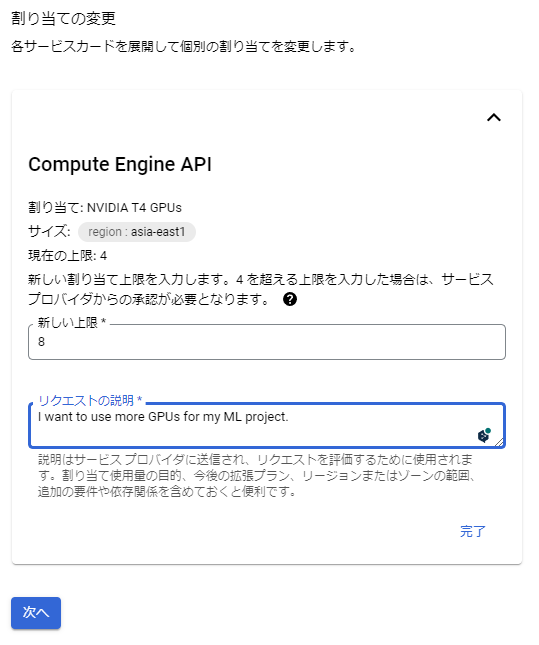
もしこの値が0になっている、あるいは同時にもっとGPUを使用したい場合は申請が必要になります。申請は、使いたいリージョンの項目の左のチェックボックスを押して、その後割り当てを編集を押します。
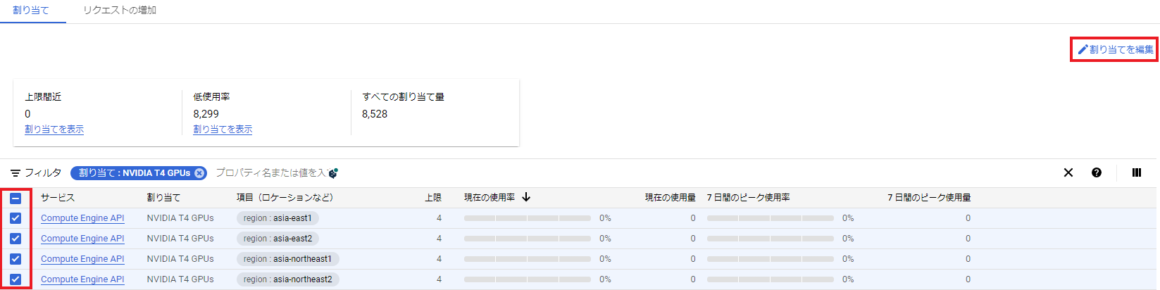
すると次のように使用したい数を入力出来る画面が表示されるので、使いたい個数と使う理由を記載し、次へボタンを押します。ちなみに、追加したいリージョンそれぞれで入力する必要があるので、本当に使いたいリージョンだけ選択するといいと思います。後はメールアドレスを入力して申請をします。基本的には5分10分で許可されたというメールが届くと思います。使用したいGPU数やリージョンが多いとサポートとのやり取りが必要になるかもしれません。
小ネタ(GPUの選び方)
- コスト重視の場合 → T4 (16GB)
- 性能を重視したい場合 → V100 (16GB)
- コスト度外視で最高性能を使いたい場合 → A100 (40GB/80GB)
そんなに大きなモデルでなければGPUメモリは16GBあれば足りると思います。超大きいモデルで16GBでも足りないようならA100を選ぶと良いと思います。A100ではGPUメモリ40GBと80GBのバージョンがあるので、扱うモデルサイズに応じて選んでください(もちろん80GB版の方が高いです)。
Compute EngineでVMを作成する
次に左のメニューからCompute Engine -> VMインスタンスを選択します。VMインスタンスページで、上の方にあるインスタンスを作成をクリックします。
次にVMインスタンスの構成を設定します。適当な名前を入力し、先ほどの割り当てをしたリージョンを選択します。ゾーンはどれでも良いですが、たまに特定のゾーンではGPUが利用できないと表示されることがあるので、その場合は違うゾーンを選んでください。次にマシンの構成は目的に応じて好きなスペックを選んでください。GPUを使いたい場合はGPU項目を選択します。
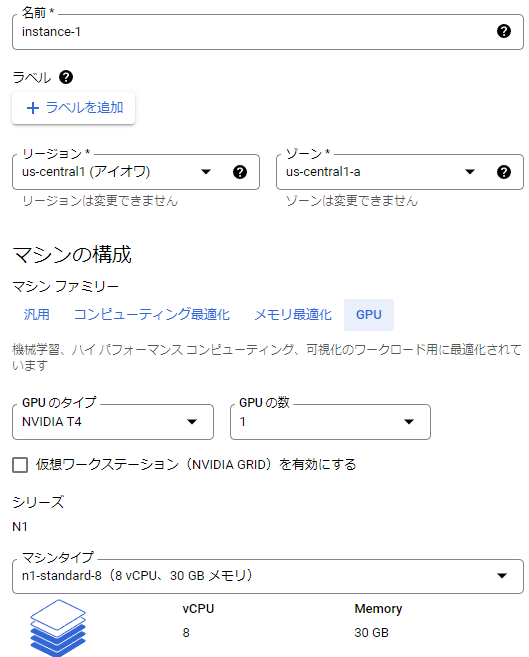
マシンタイプに関してはお好みで選択いただければと思いますが、私が良く使うのはn1-standard-8です。CPUは8個ぐらいあれば重い処理じゃなければ十分ですしメモリも30GBぐらいあれば足りることが多いです。
Confidential VMsサービスとコンテナ項目は今回はスキップで大丈夫です。
ブートディスク項目の変更をクリックします。
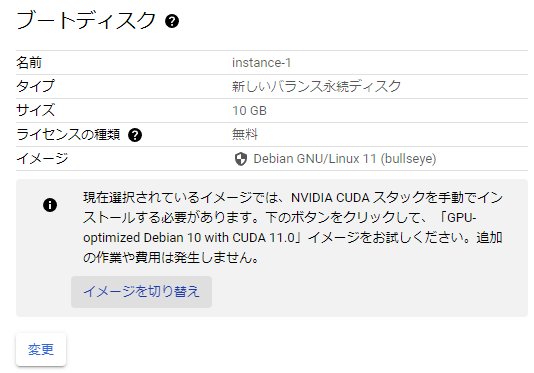
すると次のようにVMのOSやバージョン、ブートディスクのサイズを選択出来ます。このOSでおすすめなのがDeep Learning用に事前に設定されたDeep Learning on Linuxです。このOSを選ぶことで、煩雑なCUDAのインストールなどを簡単に済ますことが可能です。フィルタにdeepと入力すると見つけやすいです。
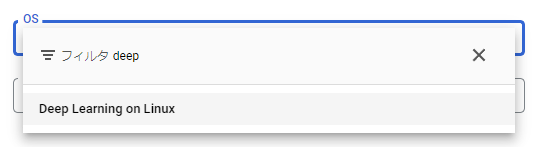
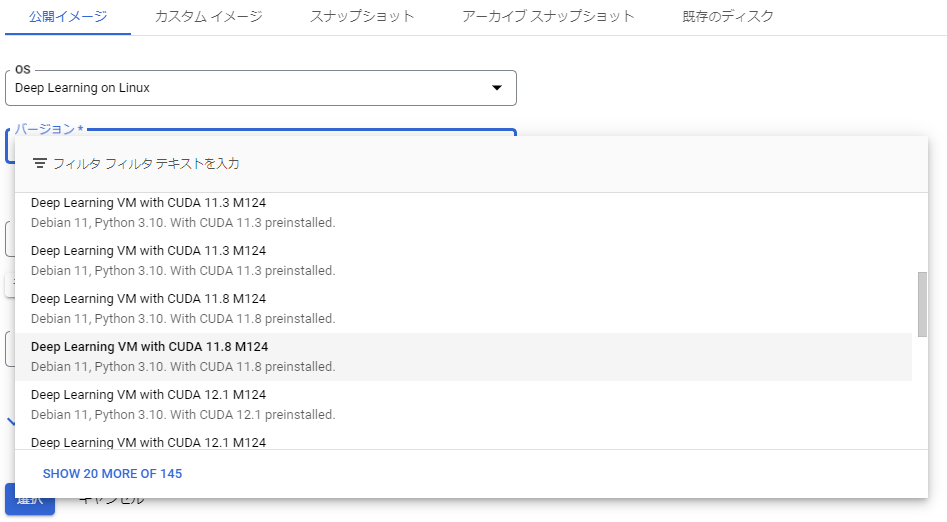
次にバージョンを選択します。それぞれ事前にインストールされるライブラリやCUDAバージョンが異なり、使用用途に応じて好きなバージョンを選択してください。どれを使えばいいか分からない場合、基本的には以下(Python3.10想定)で良いと思います。
- CPUのみの場合:
Deep Learning VM M124 - GPUの場合:
Deep Learning VM with CUDA 11.8 M124
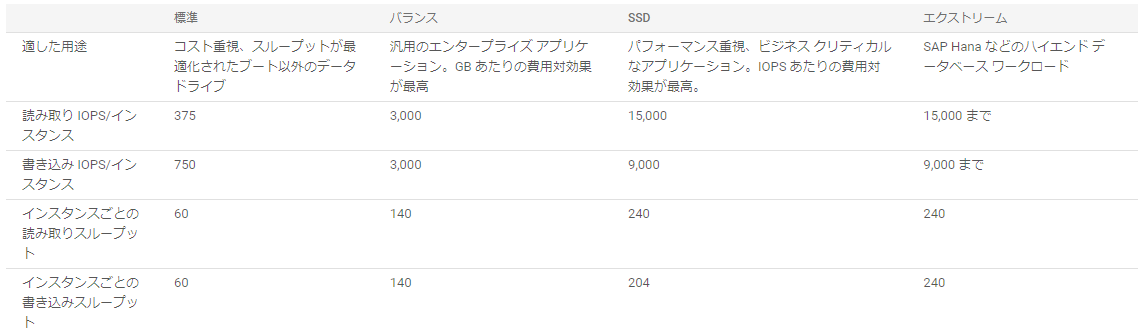
次にブートディスクの種類を選びます。コスト重視の場合は標準永続ディスク、性能重視ならSSD永続ディスクを選びます。GPUを使う場合などはDisk IOがボトルネックになることも多いので自分はSSDをよく選んでいます。
他の設定は変えずに一番下のVM作成ボタンを押すとVMインスタンスを作成できます。
エラーが発生する場合
GCPでGPUを使う場合結構エラーが発生します。例えば自分の経験では、比較的インスタンス費用が安めのアイオワでT4を使おうとしたらエラーでインスタンスを立てれませんでした。どうもその時使えるT4がアイオワになかったようです。この時はリージョンを変えてインスタンスを作るといいです。T4だと台湾はよく立てれるのでおすすめのリージョンです。
一度設定したVM設定を再活用する
GCPにはインスタンステンプレートという機能があり、これを使用することで毎回最初から設定することなく同じ設定のインスタンスを何個も作ることができます。

基本的な使用方法は通常のインスタンス作成方法と同じで、インスタンステンプレート画面から、VM作成を押すことで作成できます。

SSHの設定をする
VMインスタンスを立てた後は基本的にはSSHを使用してアクセスします。GCPのブラウザページからも一応アクセスは出来るのですが、SSHを通してアクセスした方が何かと便利だと思います。
まず、ローカルでSSH認証鍵を作成します。OSによってはssh-keygenがデフォルトで入っていなかったりするので、なければインストールしてください。
- コンソールで
ssh-keygen -t ed25519 -C ""で認証鍵を作成します。デフォルトだとRSA方式ですが、最近はより安全な鍵であるed25519方式を使うのがより推奨されていると思います。 - 次に鍵の保存場所を選びますが、今回はデフォルトの
~/.ssh/id_ed25519に保存することにします。 - 次にパスフレーズを入力します。これを設定すると、鍵での認証+パスワード認証となり2段階の堅牢な認証方法となります。ちなみにそのままEnterキーを押すとスキップすることができ、パスワード認証はしないようにすることが出来ます。自分は毎回パスフレーズを入力するのが面倒なのでパスフレーズを設定しないことが多いです。
- すると先ほど指定した場所に2つのファイルが生成されます
id_ed25519.pub: 公開鍵id_ed25519: 秘密鍵
以上の手順で、ローカルでの鍵の作成は完了です。次に、GCP上で作成した公開鍵を登録します。
GCPのCompute Engineページに行った後、左のメニューからメタデータを選択します。少しスクロールする必要があると思います。
メタデータページで上の部分の編集をクリックし、SSH認証鍵をタブを選択後に、項目を追加を押します。
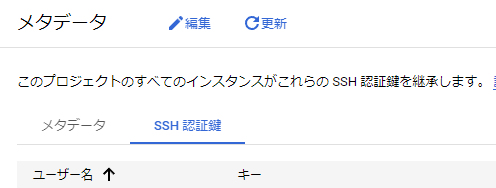
すると以下のようにSSH鍵の入力欄が出てくるので、先ほど作成したid_ed25519.pubファイルの内容をコピーし貼り付けます。入力後下の保存を押すと、SSH鍵の登録が完了となります。

最後に、インスタンスへ簡単にアクセス出来るように~/.ssh/configファイルを設定します。まず、GCPインスタンスの外部IPアドレスをコピーします。これは、Compute EngineのVMインスタンスページに行き、インスタンス一覧から外部IPの項目にマウスを重ねると簡単にコピーすることが出来ます。

次に、vim ~/.ssh/configでconfigファイルを開きます。vimを使わないで何かしらのテキストエディタでも大丈夫です。そして、以下のように記載をします。
Host gcp_test
user test_user
hostname XX.XXX.XXX.XXX
identityfile ~/.ssh/id_ed25519Hostやuserの名前は適宜変更してください。hostnameは先ほどコピーした内容を貼り付けます。そして、identityfileには先ほど作成したSSH鍵の秘密鍵を指定します。これでSSHでのアクセス設定は完了です。
試しにコンソールでssh gcp_testを打ってみるとSSH接続が出来ると思います。
VMインスタンスにアクセスする
VMインスタンスにアクセスした後は最初にこのような文字が現れます。ここでyを押すと、勝手にCUDA周りのインストールをしてくれます。(Deep Learning on Linux OSを選んだ場合)
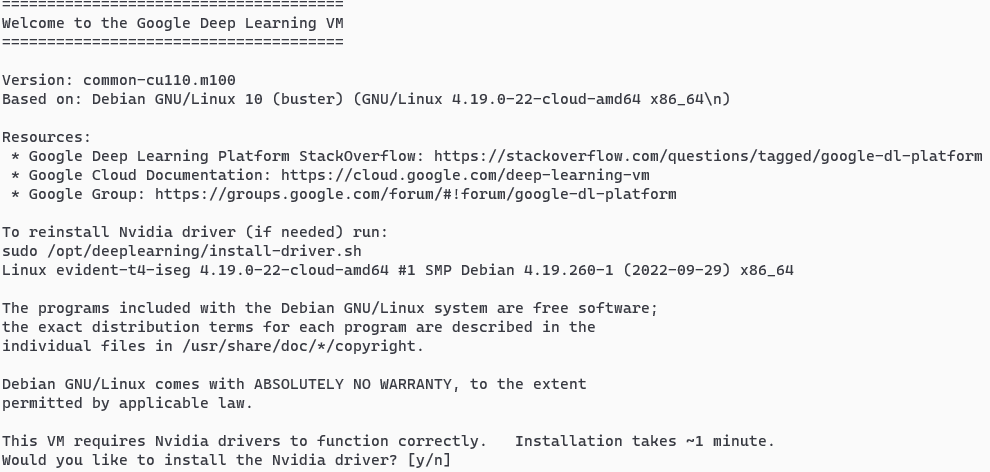
CUDA周りのセットアップが終わったら、以下のコマンドでCUDAがインストールされているか確認してみましょう!以下のような結果が出力されたら成功です!
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 63C P0 31W / 70W | 0MiB / 15360MiB | 10% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+インスタンス停止をした場合にCUDA等がリセットされてしまう場合
たまに?インスタンスを停止して再度起動した際にCUDA環境が壊れてしまうことが発生します。この場合はSSH接続時に最初にコンソールに表示される情報通り
sudo /opt/deeplearning/install-driver.shを実行すると、再度CUDA環境をインストールすることが出来ます。
開発環境の構築
ローカル開発環境
インスタンスができて、SSH接続が出来るようになってもそのまま開発する、ということはないと思います。おすすめの開発方法はVSCodeのRemote Development機能を使用しての開発です。先ほど作成した~/.ssh/configを使用できるので余計な設定をすることなく接続が出来ます。
細かいVSCodeの設定方法などは以下の記事を参考にすると良いと思います。
この方法を利用することで、裏側ではSSHで動いているのですがローカルで開発しているような感覚で開発することができます。
Github周りの作業
多くの場合、開発時にはGithubを利用すると思います。Public repositoryのみを使用する場合は問題にはならないのですが、Private repositoryを利用する場合はgithubの認証関連の作業が発生します。例えば、リモートでそのままではgit clone XXXが出来ないなど。
解決方法としては、personal access tokenを作る、ssh鍵を送付してssh設定をしてgithubにアクセスする、などがありますが手間がかかったりセキュリティ的によくなかったりします。
おすすめの方法がGit Credential Managerを使う方法です。リモートマシンで以下のようにコンソールで設定すると、簡単にgithubの認証が出来るようになります。
1. VM上でインストールします。これでインストール完了です。
curl -LO https://aka.ms/gcm/linux-install-source.sh &&
sh ./linux-install-source.sh &&
git-credential-manager configure &&
export GCM_CREDENTIAL_STORE=cache2. 任意のプライベートリポジトリをgit cloneをすると以下のように聞かれるので1を選択し、指示に従うとそのままcloneできます
Select an authentication method for 'https://github.com/':
1. Device code (default)
2. Personal access tokenおまけ:CUDA, CuDNNバージョンの確認方法
CUDAバージョンの確認で有名なnvidia-smiは実は使えるCUDAの最大バージョンらしい・・・?なのでnvcc -Vで本当のインストールされたバージョンを確認できます
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Mon_May__3_19:15:13_PDT_2021
Cuda compilation tools, release 11.3, V11.3.109
Build cuda_11.3.r11.3/compiler.29920130_0CuDNNのバージョンは以下の方法で確認できます。ちょっと見づらいのですが、以下の内容でCuDNN 8.2.0がインストールされていることになります。
$ cat /usr/local/cuda/include/cudnn_version.h
#ifndef CUDNN_VERSION_H_
#define CUDNN_VERSION_H_
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 2
#define CUDNN_PATCHLEVEL 0
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#endif /* CUDNN_VERSION_H */おまけ:CuDNNのアップグレード方法
今回紹介したDeep Learning on Linux OSですが、現時点でCuDNNのバージョンが8.2.0で、pytorchをインストールしようとすると以下のようなエラーが発生しました。
RuntimeError: cuDNN version incompatibility: PyTorch was compiled against (8, 3, 2) but linked against (8, 2, 0)エラー内容を見るとPyTorchはCuDNN8.3.2用にコンパイルされているけど、8.2.0がインストールされているよ、ということなので素直にCuDNNをアップグレードします。基本的には公式のガイドに従い以下のようにします。
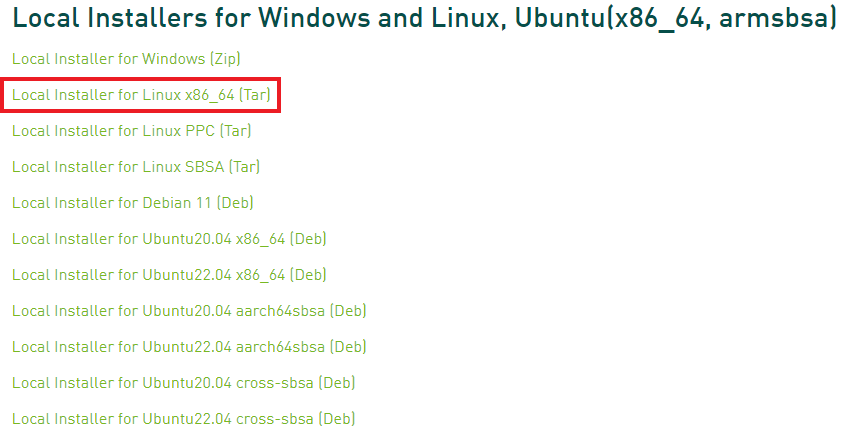
1. CuDNNのダウンロードページに行きます。ダウンロードにはNVIDIAへの登録が必要です。
2. 以下の選択肢の中からLocal Installer for Linux x86_64 [tar]を選び、まずローカルへダウンロードします
3. scp等を使いリモートへこのファイルを送信します。ファイル名はアップデートされ変わるので以下のコマンドはそのまま使えないことに注意してください。
$ scp cudnn-linux-x86_64-8.7.0.84_cuda11-archive.tar.xz user@gcp_instance:~/4. tarで解凍します。
tar -xvf cudnn-linux-x86_64-8.7.0.84_cuda11-archive.tar.xz5. 解凍されたバイナリを特定の場所にコピーします。これでアップグレード完了です!
$ sudo cp cudnn-linux-x86_64-8.7.0.84_cuda11-archive/include/cudnn*.h /usr/local/cuda/include
$ sudo cp -P cudnn-linux-x86_64-8.7.0.84_cuda11-archive/lib/libcudnn* /usr/local/cuda/lib64
$ sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*6. 一応最後にバージョンを確認してみます。無事CuDNN8.7.0になっていますね!
$ cat /usr/local/cuda/include/cudnn_version.h
#ifndef CUDNN_VERSION_H_
#define CUDNN_VERSION_H_
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 7
#define CUDNN_PATCHLEVEL 0
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)さいごに
今回の記事ではGCPを使用して爆速でAI開発環境を作成する方法を解説しました。GCPのUIはとてもすっきりしていて使いやすいので個人的にとてもおすすめです。
[告知] TC3では、Gigコミュニティとの革新的なコラボレーションでAI分野での社会実装をより進めていくAIエンジニアを大募集しています!TC3の話が聞きたい、ちょっと興味がある、社内の文化や雰囲気が知りたいという方は@mumeco_ml(ぜひフォローしてください~😊)までご連絡頂ければご相談に乗れますし、お店でお肉でも食べながらカジュアルにご紹介も可能でございます!


