
本記事は20分程度でお読みいただけます。
こんにちは。TC3データサイエンス部門の梅本です。
普段はPyTorchを使っているのですが、新しいライブラリを触るのも勉強になると思いますので、今日は新進気鋭の深層学習ライブラリであるJAX/Flaxを使って、MNISTを学習させてみようと思います。
上のコードのうち、後半の



はじめに
皆さんご存知の通り、TensorFlow、Keras、PyTorch(Chainer…)と近年は様々な深層学習ライブラリが使われています。最近、JAXというライブラリが話題になっているものの、十分すぎるライブラリがある中でなぜJAXが新たに出てきたのでしょうか?(そしてなぜ使うべきなのか)。この理由には後発ライブラリの強みとして、先行ライブラリの問題点を改良しているという点が挙げられます。現状以下のような利点が挙げられます- XLAコンパイルによる高速性
- 厳密な乱数の管理による再現性の担保
- 純Python実装による使いやすさ、デバッグのしやすさ
JAXの概要
公式リポジトリに以下のように記載があります。JAX is Autograd and XLA, brought together for high-performance machine learning research.Pythonを知っている方向けに一言で言うと、JAXとは自動微分機能とコンパイル機能が付いたNumpyです。NumpyはPythonを使っている方ならご存知の通り、行列演算を行うライブラリですが、JAXはnumpyを完全にカバーしています。ただ、単純にJAXに変えたところでJAXの恩恵はあまりなく、上述した自動微分を使うか、コンパイルを通すことでJAXの恩恵にあずかれるようになります。ここまでの説明で気づいた方も多いと思いますが、JAXはかなり低いレイヤーのライブラリであるので単体ではDeepLearningを実装するにはかなり手間がかかります。毎回CNNとかRNNとか実装してられませんよね…😥。そこで、JAXをラッパーするライブラリがいくつか開発されています。有名なところでFlax, Haiku, Traxがあるそうで、スター数的にはTraxが6.7k、Flaxが2.6k、haikuが1.7kで実はTraxが一番多かったりします。このラッパー出しているのが全部Googleということで、その組織の大きさと自由さを感じます。今回はこのうちFlaxを使って実装をしてみたいと思います。
Flaxの概要
1からしっかり学習したい方は公式ドキュメントを読むと良いと思います。ドキュメントにはFlaxの説明として以下の説明がありました。Flax is a high-performance neural network library for JAX that is designed for flexibility軽く触った感じ、PyTorchの影響を結構受けているなと感じていて、PyTorchに慣れている人であれば比較的容易にFlaxを学ぶことが出来ると思います。HuggingFaceのチームがFlax vs Pytorchのベンチマークを測っているのですが興味深いです。 一番気になるモデルの書き方はこんな感じ、いくつか書き方はあるんですが
@nn.compactデコレータを使った書き方が直観的で書きやすい気がします。
class CNN(nn.Module):
@nn.compact
def __call__(self, x):
x = nn.Conv(features=32, kernel_size=(3,3))(x)
x = nn.relu(x)
x = nn.avg_pool(x, window_shape=(2,2), strides=(2,2))
x = nn.Conv(features=64, kernel_size=(3,3))(x)
x = nn.relu(x)
x = nn.avg_pool(x, window_shape=(2,2), strides=(2,2))
x = x.reshape((x.shape[0], -1)) # flatten
x = nn.Dense(features=256)(x)
x = nn.relu(x)
x = nn.Dense(features=10)(x)
x = nn.log_softmax(x)
return xnn.Denseは全結合層で、pytorchだとnn.Linearというクラスが同じものになります。引数を見ると、pytorchのnn.Linearは最小で2つの引数が必要です。つまり、torch.nn.Linear(in_features, out_features)のように入力次元と出力次元を記載します。一方で、Flaxではnn.Dense(features)しか引数が無いんです。これは、Flaxでは出力次元だけ指定をして、入力次元はライブラリが自動的に推定してくれるのでこのような形になっています。確かに、今までは前層の出力次元をそのまま次層の入力次元に書いてたりするのでそこの重複がなくなるのは楽かもしれません。
CNNでMNISTを学習させる
では早速、Flaxを使ってMNISTを学習させるコードを書いていきましょう。Flaxの公式ドキュメントを参考にしているので、詳細が気になった方はそっちを見てみると良いと思います。 実行環境はGoogle Colaboratoryを想定しています。方針としては、まずは慣れ親しんだpytorchを使ってMNISTのデータダウンロード、DataLoaderを使おうと思います。モデル定義はFlaxを使って、最適化ライブラリにはoptaxを使います。残りの、関数適用の部分なんかはJAXで処理します。 まずは、ライブラリのインストールとインポートを行います。!pip install -U -q pip jax jaxlib
!pip install -U -q git+https://github.com/google/flax.git
!pip install -U torch torchvisionfrom tqdm import tqdm
import jax
import jax.numpy as jnp
from jax import random
from flax import linen as nn
from flax.training import train_state
import numpy as np
import optax
from torchvision.datasets import MNIST
from torch.utils.data import DataLoaderCNNのモデルは既に記事の上で定義(CNNクラス)してますので、ここでは省略します。次に、MNISTのデータを読み込むための関数を定義します。
def mnist_transform(x):
return np.expand_dims(np.array(x, dtype=np.float32), axis=2) / 255.
def mnist_collate_fn(batch):
batch = list(zip(*batch))
x = np.stack(batch[0])
y = np.array(batch[1])
return x, y定義した関数を使ってMNISTを変数に入れ込みます。
train = MNIST(root='train', train=True, transform=mnist_transform, download=True)
test = MNIST(root='test', train=False, transform=mnist_transform, download=True)
train_loader = DataLoader(train, batch_size=64, shuffle=True, collate_fn=mnist_collate_fn)
test_images = np.expand_dims(jnp.array(test.data), axis=3)
test_lbls = jnp.array(test.targets)次が重要なんですが、FlaxではDeep Learningをするうえでよく使うような作業のラッパーするクラスを提供しています。例えば、モデルにデータを流してパラメータを更新する、なんてコードはどのDeep Learningでも出てくると思いますが、このラッパークラスを使うことで何度もここの部分のコードを書く必要がなくなります。
def create_train_state(key, learning_rate, momentum):
cnn = CNN()
params = cnn.init(key, jnp.ones([1,28,28,1]))['params']
tx = optax.sgd(learning_rate, momentum)
return train_state.TrainState.create(apply_fn=cnn.apply, params=params, tx=tx)まず、気づいた方がいると思いますが、Flaxの特徴として、モデルと実パラメータが切り離されていることが挙げられます。pytorchだと、モデルクラスを定義したらそのクラスの変数としてパラメータが含まれますが、Flaxだとモデルクラスは純粋な関数になっており、毎回引数でモデルのパラメータを要求します。ラッパーのクラスはreturnのところに書かれている
TrainStateクラスで、.createでは、モデル、パラメータ、そして最適化アルゴリズムをここに記載します。そして、恐ろしいのがこのクラスを使ってしまえばとても簡単にパラメータをアップデートしていくことができます😍次に、1stepを扱う関数を書いていきます。
def compute_accuracy(logits, y):
accuracy = jnp.mean(jnp.argmax(logits, -1) == y)
return accuracy
@jax.jit
def train_step(state, x, y):
def loss_fn(params):
logits = CNN().apply({'params':params}, x)
one_hot_labels = jax.nn.one_hot(y, num_classes=10)
loss = -jnp.mean(jnp.sum(one_hot_labels * logits, axis=-1))
return loss, logits
(loss, logits), grads = jax.value_and_grad(loss_fn, has_aux=True)(state.params)
state = state.apply_gradients(grads=grads)
metrics = {
'loss': loss,
'accuracy': compute_accuracy(logits, y),
}
return state, metrics
@jax.jit
def eval_step(state, x, y):
logits = CNN().apply({'params':state.params}, x)
return compute_accuracy(logits, y)1つ目の
compute_accuracy関数は単にlog_softmax層の出力をラベルに変換して、その精度を計算しています。2つ目のtrain_step関数は、まず誤差関数を定義して、jax.value_and_gradで誤差関数を通した結果(loss)と勾配情報を計算して、state.apply_gradientsでその勾配を使ってパラメータを更新しています。3つ目のeval_step関数は、モデルにパラメータを渡しつつ出力を得て、精度を計算しています。次に、1epochを扱う関数を書いていきます。
def train_epoch(state, dataloader, epoch):
batch_metrics = []
with tqdm(total=len(dataloader)) as tq:
for cnt, (x, y) in enumerate(dataloader):
tq.update(1)
state, metrics = train_step(state, x, y) # update state
batch_metrics.append(metrics)
batch_metrics_np = jax.device_get(batch_metrics)
epoch_metrics_np = {
k: np.mean([metrics[k] for metrics in batch_metrics_np])
for k in batch_metrics_np[0]
}
return state, epoch_metrics_np
def evaluate_model(state, x, y):
metrics = eval_step(state, x, y)
metrics = jax.device_get(metrics)
metrics = jax.tree_map(lambda x: x.item(), metrics) # np.ndarray -> scalar
return metricsあまり書くところもないですが、pytorchのdataloaderを使ってバッチを作成してそれを先ほどの1stepの関数へ流しています。1stepの関数でパラメータ更新を行うのでここでは、metricsを計算する以外は何もしないです。あと、重要なのがJAX/FlaxではバックエンドのGPUを勝手に使ってくれるので(明示的に指定することも可能です)、
jax.device_get関数を使ってGPUメモリからCPUメモリへ変数を変換しているのもポイントです。最後に、各種ハイパーパラメータを記載して、epochを回します。
learning_rate = 0.1
momentum = 0.9
num_epochs = 3
batch_size = 32
key = random.PRNGKey(0)
state = create_train_state(key, learning_rate, momentum)
for epoch in range(1, num_epochs + 1):
state, train_metrics = train_epoch(state, train_loader, epoch)
print(f"Train epoch: {epoch}, loss: {train_metrics['loss']:.4}, accuracy: {train_metrics['accuracy'] * 100:.4}")
test_metrics = eval_step(state, test_images, test_lbls)
print(f"Test epoch: {epoch}, accuracy: {test_metrics * 100:.4}")JAXの特徴で、乱数の管理が厳密なので、全ての乱数生成に生成鍵を要求します。なので、
random.PRNGKey関数でその鍵を事前に生成しています。本当は、データセットの分割(DataLoaderのとこ)もJAXの乱数を使って分割すると、完全に再現できるように分割が出来るのですが、今回は再現性は求めていないのでそこは妥協しています。結果
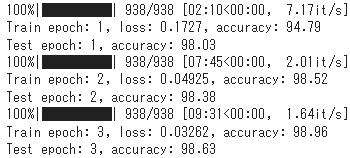
上記のセルを動かすと以下のような結果が得られます。Colaboratoryだと、CPU/GPU/TPUが選べるので3種類比較しています。
CPU
GPU
TPU
速度を比較すると、TPU > GPU > CPUの順で早かったです。どのクラスのGPUが割り当てられたかという点が重要なので、一概にTPU>GPUとは言えませんが、今回はこのような結果になりました。ちなみに、JAXのXLAコンパイルを外した状態で動かしてみると速度は1/2以下になってしまいました😅
まとめ
今回はGoogle発の新進気鋭の深層学習ライブラリJAX/Flaxを使ってMNISTを学習させてみました。nn.compactで思ったより簡単にモデルが定義出来たり、TrainStateクラスによって簡潔にパラメータの更新が出来るのがとても快適でした。一方で、まだまだ発展途上のライブラリなのでPyTorchほど様々なコンポーネントが充実しているわけではなく、最先端のコンポーネントを組み込みたい場合は、多くの部分を自分で実装しないといけなかったりする場面があるかもしれません。今後の発展に期待ですね。
TC3では、Gigコミュニティとの革新的なコラボレーションでDataScience/AI分野での社会実装をより進めていくAIエンジニアを大募集しています!TC3の話が聞きたい、ちょっと興味がある、社内の文化や雰囲気が知りたいという方は@mumeco_mlまでご連絡頂ければDMでご相談に乗れますし、お肉でも食べながらご紹介なども出来ると思いますのでよろしくお願いいたします!
詳細のご紹介資料はこちら

詳細は以下のフォームからダウンロード可能です。


